




#seenthis_bug ?
@seenthis, pourquoi le moteur de recherche ne me trouve pas les post quand je fais une recherche avec un tag qui pourtant existe ?
Voici en images :

–-

–-
#seenthis_bug ?
@seenthis, pourquoi le moteur de recherche ne me trouve pas les post quand je fais une recherche avec un tag qui pourtant existe ?
Voici en images :

Ah ça m’intéresse ! J’avais déjà remarqué ça mais je mettais ça sur le compte de ma non compréhension du moteur de recherche #seenthis

Oui, il y a réellement un bug. Il y a juste une minute, je lance une recherche avec les mots « hugo » et « clément », on me ressort une liste de seens où apparaissent en surbrillance des adverbes terminés par -ment ...

Il n’y a des bugs ou des améliorations différentes là dedans :
– pour « haps » c’est clairement un bug puisque c’est le tag exact, et donc ça devrait forcément le sortir, là ya un vrai soucis
– pour « high-altitude » c’est différent, le tag n’existe pas, mais un autre le contenant existe. Or le listing de ce qui contient un début de tag, ça ne marche QUE sur « /tag/truc », pas du tout dans le moteur de recherche (en arrière plan, /tag/truc utilise directement la base de données de SPIP, tandis que dans le moteur de recherche ça n’utilise que ce qui vient du moteur d’indexation Sphinx, et dans lequel pour l’instant on n’a pas intégré ce système de débuts de tags)
– pour « clément » c’est un problème d’encodage que j’ai déjà eu sur un serveur une fois, les accents n’étant plus reconnus par Sphinx, ça cherche alors « cl », et « ment », séparément, comme si l’accent était un espace au milieu. Pour ça la solution a été de passer à Manticore, un fork de Sphinx plus mieux libre et mieux maintenu

#merci @rastapopoulos en espérant que cela ne vous prenne pas trop de temps et énergie pour réparer le bug

Concernant #haps la page du tag liste bien le post concerné cf ►https://seenthis.net/tag/haps
Par contre, la recherche est bien pété, ce qui pourrait s’expliquer par un problème d’indexation du post, espérons que qu’une personne qui maîtrise sphinx pourra s’y pencher (ça ne sera pas moi sur ce coup là, c’est hors de mes compétences).
Mais, la recherche sur le tag sans # fonctionne bien ▻https://seenthis.net/recherche?recherche=haps&follow=cdb_77
Je me demande si la recherche est bien prévue pour chercher les tags avec un #

quand on met un # c’est un comportement dérogatoire, @fil avait codé que ça le détectait (un seul) et ça l’ajoutait en filtre sphinx dans les tags indexés (et non pas en recherche libre donc)

J’ajoute que le serveur est en debian particulièrement vieille. Et plutôt que de la mettre à jour, on pourrait en installer une toute nouvelle, avec les dernières versions de tous ces outils. Je ne sais pas si ça pourrait aider, mais ça ne pourrait pas faire de mal à coup sûr.
@rastapopoulos je mets tout le temps les # dans la recherche quand je cherche, justement, un tag précis... à éviter donc, si je comprends bien ton commentaire ? Mais du coup, comment faire une recherche précise de tag ?


@cdb_77 tout dépend si tu cherches à le coupler à de la recherche libre aussi ou pas, dans ce cas c’est ce que tu fais, dans « le moteur de recherche », où tu peux ajouter de la recherche libre, un filtre sur tel compte etc
mais si c’est juste pour chercher uniquement un tag, faut aller… sur la page dédiée du tag :) comme l’a lié @b_b juste au-dessus
mmmhhh... pas très clair pour moi...
j’avais suivi ce conseil :
« Il est possible de demander un tag ou les messages écrits par un auteur précis en ajoutant directement dans la recherche le code #tag »
►https://seenthis.net/francais/article/moteur-de-recherche
car pour ça :
pour chercher uniquement un tag, faut aller… sur la page dédiée du tag :)
ça veut dire qu’il faut que je tape (manuellement en gros) sur la barre menu :
▻https://seenthis.net/tags/haps ?
Et en fait, même si je fais cela... apparaît dans la liste ce post :
▻https://seenthis.net/messages/810395
Dans ce post il n’y a pas #haps, mais :
outside of perhaps the modish cubism of Sophia Delaunay. So I’m posting them here. Enjoy
–-> perhaps, donc ! ;-)
euh non l’URL que t’as mis là c’est une page 404 (qui montre une recherche sur les mots de l’URL pour essayer de montrer un contenu pertinent quand même)
b_b t’as mis l’URL juste plus haut mais t’as pas à le taper dans l’URL, tu as remarqué que tous les tags étaient des liens cliquables qui avaient alors leur propre page dédiée ? (il te suffit de cliquer sur ton propre « haps » là juste dans ton message qui précède)
mmhhh... en effet, j’avais pas vu, page 404... j’ai fait une erreur, je voulais mettre celle-ci :
►https://seenthis.net/tag/haps
(et du coup, ça marche, j’ai l’impression, ça ne met que des résultats pertinents)

@biggrizzly oui à bloc pour une mise à jour de la machine quand tu veux/peux, fais moi signe si je peux t’être utile.


Archives d’Anna
Moteur de recherche des #bibliothèques_clandestines : livres, journaux, BD, magazines. ⭐️ Bibliothèque #Z-Library, #Bibliothèque_Genesis, #Sci-Hub. ⚙️ Entièrement résilient grâce à un code et à des données open source.
#édition_scientifique #livres #articles #moteur_de_recherche #z-lib #libgen

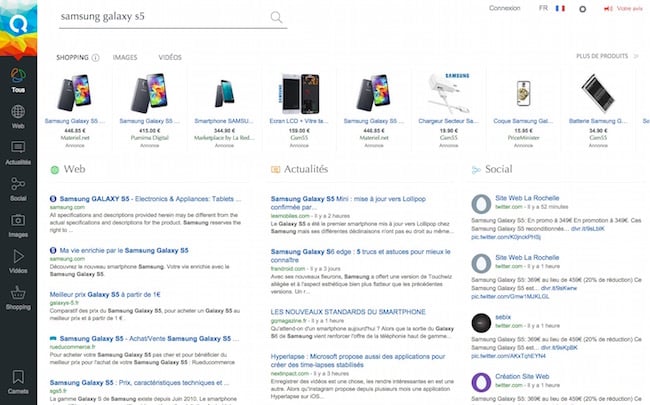
Les moteurs de recherche - Épisode 3 : Rechercher des images sur Internet | Ascodocpsy
▻https://www.ascodocpsy.org/allo-la-doc-8-les-moteurs-de-recherche-episode-3-rechercher-des-images-s
Dans cet épisode 3, toujours consacré aux moteurs de recherche web, nous continuons à vous dévoiler des astuces d’interrogation plus spécifiques, avec un focus sur la recherche d’images.
Question technique à @seenthis (#seenthis_bug) concernant le #moteur_de_recherche (ce problème a été déjà soulevé par moi-même par le passé)
ici : ▻https://seenthis.net/messages/676873
ici : ▻https://seenthis.net/messages/656397
et ici : ▻https://seenthis.net/messages/622190
Je cherche un post que j’ai ajouté ce matin... et je savais qu’un des mots-clé étaient « humiliation ». Je vais donc sur l’outil « recherche » et je tape « #humiliation ».
Résultat ici :
▻https://seenthis.net/recherche?recherche=%23humiliation%20&tag=%23humiliation
Premier article qui apparaît, un article posté par Simplicissimus il y a 4 mois... et pas de trace de l’article que je cherche :
Par contre, si je mets dans le moteur de recherche google « #humiliation seenthis.net »...
... je tombe directe sur le tag #humiliation :
Et si je clique... je trouve direct l’article que je cherchais, celui-ci :
why ?
Si vous avez des réponses, ça serait super de chez super, car le moteur de recherche seenthis est trop précieux !!!
ping @fil
Les moteurs de recherche — fonctionnement et #controverses
▻https://fadoc.univ-toulouse.fr/course/view.php?id=55
Apprendre comment les moteurs de recherche du web fonctionnent.
Connaître l’écosystème duquel ils participent
Comprendre les principales controverses dont leur activité fait l’objet (neutralité, opacité, concurrence, données, responsabilité, droit d’auteur)

How the CIA made Google - INSURGE intelligence - Medium
▻https://medium.com/insurge-intelligence/how-the-cia-made-google-e836451a959e
INSURGE INTELLIGENCE, a new crowd-funded investigative journalism project, breaks the exclusive story of how the United States intelligence community funded, nurtured and incubated Google as part of a drive to dominate the world through control of information. Seed-funded by the NSA and CIA, Google was merely the first among a plethora of private sector start-ups co-opted by US intelligence to retain ‘information superiority.’ The origins of this ingenious strategy trace back to a secret (...)
#Google #CIA #NSA #USDepartmentofDefense-DoD #anti-terrorisme #surveillance

Attention : 2015 !
How the CIA made Google
Nafeez Ahmed, Medium, le 22 janvier 2015
Suite :
Why Google made the NSA
Nafeez Ahmed, Medium, le 22 janvier 2015
▻https://medium.com/insurge-intelligence/why-google-made-the-nsa-2a80584c9c1
Sur le même thème :
Google’s true origin partly lies in CIA and NSA research grants for mass surveillance
Jeff Nesbit, Quartz, le 8 décembre 2017
►https://seenthis.net/messages/651183
Traduite ici :
La véritable origine de Google repose partiellement sur des bourses de recherche sur la surveillance de masse allouées par la CIA et la NSA
Jeff Nesbit, Quartz, le 8 décembre 2017
►https://seenthis.net/messages/713836
Et, juste pour rire :
Le président de Google devient conseiller pour le Pentagone
Le Figaro, le 3 mars 2016
►https://seenthis.net/messages/466670
#surveillance #google #CIA #NSA #origin_stories #recherche et d’autres discussions sur les #moteur_de_recherche #critiques_de
Je suggère de passer à #Searx, comme discuté ici :
►https://seenthis.net/messages/641417
►https://seenthis.net/messages/651183
►https://seenthis.net/messages/665962
Le site d’évaluation des versions de Searx est ici :
►https://asciimoo.github.io/searx/user/public_instances.html
Les add-ons de Searx sur firefox sont là :
►https://addons.thunderbird.net/en-us/firefox/search/?q=searx&appver=72.0&platform=linux
Du coup, je passe à :
►https://searx.prvcy.eu
#WSWS #optimisation de #firefox

searx stats
▻https://stats.searx.xyz
This is a little website, to show up-to-date informations about public #searx_Instances.
#Searx is a #free_internet #metasearch_engine which aggregates results from more than 70 search services. Users are neither tracked nor profiled.
via (l’inévitable) @sebsauvage

La véritable origine de Google repose partiellement sur des bourses de recherche sur la surveillance de masse allouées par la CIA et la NSA
▻https://www.les-crises.fr/la-veritable-origine-de-google-repose-partiellement-sur-des-bourses-de-re
How the CIA made Google
Nafeez Ahmed, Medium, le 22 janvier 2015
►https://seenthis.net/messages/821822
Why Google made the NSA
Nafeez Ahmed, Medium, le 22 janvier 2015
►https://seenthis.net/messages/821822
#surveillance #google #CIA #NSA #origin_stories #recherche et d’autres discussions sur les #moteur_de_recherche #critiques_de
Petite question concernant le #moteur_De_recherche de @seenthis.
J’ai fait une recherche avec le tag #liberland étant connectée à seenthis et voici le résultat :
J’ai montré seenthis à un étudiant, qui a fait la même chose en n’étant pas connecté et voici son résultat :
Pourquoi cette différence ?
#seenthis_bug (?)

Qwant, l’anti-Google français, jouera quitte ou double en 2018
►https://www.usine-digitale.fr/article/qwant-l-anti-google-francais-jouera-quitte-ou-double-en-2018.N643093
Qwant avait également passé quatre partenariats avec des fabricants de smartphones et opérateurs télécom pour être installé par défaut sur les téléphones, mais ils sont tombés à l’eau lorsque Google a menacé de leur refuser l’utilisation des Google Services (la partie propriétaire d’Android, dont il est quasi-impossible de se passer aujourd’hui).
DuckDuckGo, le canard aux pratiques boiteuses | Franck Ridel
▻http://franck-ridel.fr/duckduckgo-le-canard-aux-pratiques-boiteuses
Loin de moi l’idée de les faire passer pour des menteurs qui profitent de la crédulité des gens, leurs intentions sont peut-être bien réelles après tout, mais une chose pourtant importante est souvent mise de côté.
L’avertissement (ou le rappel) est nécessaire, mais pour une utilisation d’une personne lambda au quotidien, Duckduckgo est quand même beaucoup moins evil que Google.
Je l’utilise depuis longtemps, il s’améliore régulièrement dans l’interface et les fonctionnalités, et l’utilisation des bangs (!spip) est bien agréable.
Pour le coup de Searx (méta moteur open source) installé en local, je ne connais pas bien mais j’imagine que les requêtes de recherche partent de notre machine, du coup niveau privacy ça doit pas être top...
Je n’avais pas vu la réponse dans les commentaires :
« Searx en localhost soit via proxychains, soit en reverse proxy via Tor (Ce qu’on appelle un service caché) »
Pas très grand public, difficile de conseiller ça à notre entourage d’utilisateurs lambda.
Je continue à promouvoir Duckduckgo (et Qwant) autour de moi, déjà pour montrer aux gens qu’il existe une vie hors de Google.
Bon, faudrait pas non plus flinguer DDG avec un bad buzz.
Et il faudrait surtout voir qui pourrait en être à l’origine :
Duck Duck Go dispose d’une certaine notoriété aux Etats-Unis et se positionne sur un registre pratiquement identique à celui de Qwant : le respect de la vie privée, sans tracking des utilisateurs. Une comparaison qui fait bouillir Eric Léandri. « C’est juste un méta-moteur hébergé sur Amazon Web Services. C’est du Canada Dry. Si le gouvernement américain veut des données, il n’a qu’à demander à Amazon, sans même passer par Duck Duck. »

J’ai startpage en moteur par défaut et je suis plus satisfait des résultats qu’avec DDG ou Qwant. Qwant était pénible à utiliser avec TOR (fréquent refus de connexion) et l’interface est trop distrayante.
Searx me semble le plus abouti en termes de principe mais c’est plus difficile à mettre en place. J’ignorais que LDQN avait une instance, je vais essayer.
Discussion sur le choix du #moteur_de_recherche ici aussi :
►https://seenthis.net/messages/641417
►https://seenthis.net/messages/651183
Moi je suis passé à #Searx pour les raisons que j’explique :
–il ne doit pas juste utiliser le moteur de #google
–il existe en français
–il doit avoir un onglet « actualité »
Si ça marche, quand on cherche « World Socialist Web Site » (avec les guillemets) dans l’onglet actualité, on doit trouver des articles de ce site, ce qui n’est pas le cas avec Google. Ce n’est pas que je suis obsédé par #WSWS, c’est juste un test.
Certes, c’est plus lent et moins joli que google, la version française ne marche pas toujours, et parfois il faut s’y reprendre à deux fois, mais ça va...
#optimisation de #firefox
Intéressant ces retours...
Je n’avais pas testé Searx depuis longtemps, ça s’est bien amélioré il me semble.
Manquerait plus qu’un thème dark (comme celui de DDDG) et ce serait parfait.
Si j’ai cinq minutes, j’en proposerais peut être un à #infini :)
Nouveau tag : #critiques_de pour recenser les critiques de #facebook, #google and co :
►https://seenthis.net/messages/670745
Depuis quelques temps, quand j’utilise #searx, les résultats sont moins bons, voire nuls et remplacés par la réponse suivante :
Erreur ! Les moteurs ne peuvent récupérer de résultats.
google (unexpected crash : CAPTCHA required)
Veuillez réessayer ultérieurement, ou utiliser une instance différente de searx.
Est-ce que vous comprenez le problème, et qu’est-ce que c’est une « instance différente de searx » ?
Merci !
Sur les conseils de @b_b je suis passé à ►https://searx.site mais 5 mois plus tard, à son tour de déconner. Comment savoir ceux qui marchent pour ne pas vous embêter à chaque fois ?
Cette liste les compilent :
►https://github.com/asciimoo/searx/wiki/Searx-instances
Il faut aussi qu’il existe comme « add on » de firefox, et du coup, en ce moment, je n’ai le choix qu’entre searx.me et searx.site Du coup, je repasse à searx.me... à suivre...
Le nouveau site d’évaluation des versions de Searx est ici :
►https://asciimoo.github.io/searx/user/public_instances.html
Les add-ons de Searx sur firefox sont là :
►https://addons.thunderbird.net/en-us/firefox/search/?q=searx&appver=72.0&platform=linux
Du coup, je passe à :
►https://searx.prvcy.eu
Le moteur de recherche Qwant est maintenant préconisé par le CNRS en remplacement de Google :
REVUE D’ACTUALITES CYBERSECURITE, le 2 mars 2020
Qwant est une startup française qui fournit un moteur de recherche du
même nom qui donne la priorité à la vie privée de l’utilisateur. Il a
été mis en ligne en version définitive le 4 juillet 2013.
Qwant vise à offrir la première alternative européenne crédible face aux
grandes plateformes américaines qui dominent les services sur internet.
Elle souhaite offrir au monde une vision panoramique et neutre
d’internet pour décloisonner les sources d’informations et refléter
toute la richesse du web en une seule page.
Les forces de Qwant
Le principal avantage de ce moteur de recherche est qu’il ne trace pas
ses utilisateurs. Contrairement à Google, l’historique des recherches
n’est pas conservé, il est seulement mémorisé sur le PC ou le téléphone
et aucun cookie n’est installé sur l’ordinateur. En comparaison, chez
Google, ces cookies de traçage permettent de mieux vous connaître et
suscitent un véritable intérêt publicitaire.
Qwant garantit l’anonymat. Cela veut dire pour l’utilisateur que les
résultats affichés n’ont pas été biaisés selon son profil, que le même
web est présenté à tout le monde, tel qu’il est, sans préjuger de qui
recherche l’information. Il y a très peu de publicités affichées, et
celles qui le sont sont basées uniquement sur la recherche ponctuelle,
sans aucun ciblage sur l’individu.
Qwant ne s’interdit pas de collecter des données et de les analyser,
mais s’interdit simplement de récupérer les données qui ont un caractère
personnel. Ils utilisent de la publicité contextuelle basée sur le
contenu qui est consulté ou recherché, et non sur le profil de la
personne qui le consulte ou le recherche.
Qwant apporte une réelle évolution et des apports ergonomiques qui le
placent avant Google. Lorsque l’on effectue une recherche sur internet
avec Google il y a très souvent plusieurs pages de résultats. Quand les
résultats semblent trop éloignés de la demande, Qwant affiche ce message
« Les résultats suivants sont surement peu pertinents, veuillez
reformuler votre requête. ». Une astuce qui fait gagner un temps très
précieux aux utilisateurs.
Qwant offre également la possibilité très appréciable, avec la fonction
« tous » de faire des recherches en utilisant trois moteurs indépendants
en même temps dont les résultats sont présentés sur la même page dans
trois colonnes : web, actualités, réseaux sociaux. Il est très
intéressant, pour une même recherche, de pouvoir comparer comment le
même sujet est couvert en parallèle dans les trois médias.
Les faiblesses de Qwant
Une des faiblesses de Qwant se trouve dans la recherche d’images. Elle
est nettement moins performante que Google et cela pour plusieurs
raisons. Tout d’abord on ne peut pas choisir d’afficher un format
spécifique, comme vous le propose Google avec l’affichage de JPG ou PNG.
Le choix des tailles d’images à afficher est lui aussi trop restreint
par rapport au leader et il n’y a pas d’option de filtre des couleurs.
De plus, Qwant produit moins de résultats que son concurrent Google,
leader sur le marché.
Les partenariats du moteur de recherche français
En 2015, Qwant Junior a été lancé. Les enfants âgés de 6 à 12 ans
peuvent chercher, fouiller pour dénicher des infos spécifiques à leur
tranche d’âge. Pas de censure pour autant, l’idée est avant tout de
protéger les enfants des dérives de la toile.
Installé par défaut comme navigateur de recherche dans l’Éducation
nationale, la version 1 de Junior a touché 4 millions d’enfants sur 6
millions. Un choix éminemment stratégique. Pour pouvoir survivre au
milieu des Google et autres Bing, Qwant a donc choisi de séduire les
enfants dans l’espoir de les laisser convaincre leurs parents.
Au-delà de la population junior, Qwant a su séduire certaines
universités. L’Université de Nantes par exemple, a équipé ses postes
informatiques avec le moteur de recherche Qwant. Le moteur de recherche
français vient également de signer une convention avec l’UCP,
l’université de Cergy-Pontoise. De ce partenariat nait la chaire « Data
analytics » qui permettra aux chercheurs du laboratoire ETIS
(UCP-ENSEA-CNRS) d’approfondir leurs recherches sur la fouille de
contenus textuels sur le web et les réseaux sociaux ainsi que sur
l’indexation par l’image.
Après avoir été adopté par le ministère des Armées et l’Assemblée
Nationale, l’Etat vient de faire confiance une nouvelle fois au moteur
de recherche français. Le directeur interministériel du numérique a
requis de tous les directeurs d’administration chargés du numérique
qu’ils installent « par défaut le moteur de recherche Qwant sur
l’ensemble des terminaux, fixes et mobiles » dont ils ont la charge.
Le Français Qwant devient le moteur de recherche officiel des directions
des systèmes d’information (DSI) de l’État et de l’administration
française. Il s’agira donc de la solution proposée par défaut sur les
ordinateurs utilisés par les fonctionnaires.
Comment choisir son moteur de recherche ?
Impossible de faire une liste de moteurs de recherche sans faire une
petite sélection et répondre à la question suivante : quel est le
meilleur moteur de recherche ? Les aspirations, les besoins et les
habitudes de navigation sont propres à chacun. Par conséquent, il en
résultera un choix différent. Il est nécessaire d’étudier le marché
avant de pouvoir répondre.
Il existe plusieurs moteurs de recherche tout à fait convenables, autres
que Google ou Qwant. On notera par exemple :
Lilo : Un moteur de recherche philanthropique qui redistribue ses
revenus à la guise des internautes.
Quora : Un moteur de questions-réponses enrichi par le système collaboratif.
Yippy : Moteur de recherche qui trie les résultats en dossier selon les
besoins de l’internaute.
Ecosia : Un moteur de recherche allemand qui s’engage auprès de la cause
environnementale.
Depuis quelques mois, Qwant est le moteur préconisé par la DINUM aux
services centraux de l’Etat. Il est donc également préconisé pour le
CNRS, en remplacement de Google.
Sources complémentaires :
?_▻https://www.futura-sciences.com/tech/actualites/internet-moteur-recherche-qwant-histoire-malentendu-44939/_
?_▻https://www.archimag.com/veille-documentation/2020/02/11/google-qwant-moteur-recherche-choisir-2020_
?_▻https://www.laprovence.com/article/societe/5720608/qwant-moteur-de-recherche-europeen-tout-terrain.html_
?_▻https://www.developpez.com/actu/285927/Le-francais-Qwant-qui-reve-de-detroner-le-moteur-de-recherche-de-Google-est-dans-la-tourmente-les-actionnaires-du-groupe-exigeraient-une-nouvelle-equipe-manageriale-pour-conduire-sa-transformation/_
?_▻https://www.lemonde.fr/pixels/article/2020/01/09/qwant-par-defaut-dans-les-ordinateurs-de-l-etat_6025332_4408996.html_
?_▻https://www.journaldunet.com/solutions/reseau-social-d-entreprise/1031619-comment-choisir-son-moteur-de-recherche/_
?_▻https://www.clubic.com/internet/actualite-882100-qwant-moteur-recherche-administration-francais.html_
?_▻https://unnews.univ-nantes.fr/l-universite-de-nantes-equipe-ses-postes-informatiques-avec-le-mo
?▻https://www.u-cergy.fr/fr/universite/actualites/la-societe-qwant-s-associe-a-l-ucp.html__
Encore un petit problème survenu aujourd’hui.
Je cherchais avec le #moteur_de_recherche #seenthis le film Nothing to hide. J’ai fait plusieurs recherches, mais pas trouvé le film.
Notamment, une recherche avec les mots clé : #surveillance_de_masse et #film.
Le seul post qui apparaît est celui-ci :
Or, quand j’ai mis sur google :
►https://seenthis.net/messages/634608
#seenthis_bug ou c’est moi qui fait quelque chose de faux ?
ça me rappelle ce qui avait été signalé ici :
▻https://seenthis.net/messages/640849
Mais qui a été résolu, je ne sais pas si quelqu’un avait fait quelque chose...

Google’s true origin partly lies in CIA and NSA research grants for mass surveillance, by Jeff Nesbit — Quartz
►https://qz.com/1145669/googles-true-origin-partly-lies-in-cia-and-nsa-research-grants-for-mass-surveill
►https://qzprod.files.wordpress.com/2017/08/rts18wdq-e1502123358903.jpg?quality=80&strip=all&w=1600
Did the CIA directly fund the work of Brin and Page, and therefore create Google? No. But were Brin and Page researching precisely what the NSA, the CIA, and the intelligence community hoped for, assisted by their grants? Absolutely.
The CIA and NSA funded an unclassified, compartmentalized program designed from its inception to spur something that looks almost exactly like Google.
To understand this significance, you have to consider what the intelligence community was trying to achieve as it seeded grants to the best computer-science minds in academia

Au début de Google, il y avait d’autres moteurs de recherche (altavista par exemple) presque aussi bons, et ce n’est pas le petit avantage qu’avait Google qui permet d’expliquer son succès à plates coutures...
En revanche, si la CIA a créé et financé Google, cela explique les moyens gigantesque mis à sa disposition pour acquérir les #Big_Data avec lesquelles elle a acquis ses compétences (pensez par exemple aux photos de chaque maison de chaque rue de chaque ville de chaque pays de toute la planète !), son pouvoir et, en retour, sa fortune, avec au passage la mise au ban de tous ses concurrents.
Je m’en doutais un peu, mais ce genre d’article permet de remonter le scénario. Aujourd’hui encore, Google travaille donc de concert avec la CIA, comme en témoigne le passage d’Eric Schmidt, ancien PDG de Google et actuel président d’Alphabet, comme conseiller officiel pour le Pentagone...
►https://seenthis.net/messages/466670
En même temps, c’est aussi l’armée américaine qui a inventé internet, ce n’est pas si étonnant qu’ils veuillent que ça leur soit utile. A nous de le savoir et d’en tenir compte...
C’est un peu plus fin, quand même, quand c’est apparu, ils se sont basés sur des recherches (scientifiques) qui aboutissaient à une manière bien différente de trier la pertinence des résultats par rapport aux concurrents. Donc quand on allait dessus, dans pas mal de cas « ça marchait mieux ». C’est quand même un facteur important d’adoption (et qui a abouti à la base utilisateur permettant le big data). Mais ils ont misé sur le bon cheval…
Ca marchait un peu mieux, certes, mais en général on était habitués à ce que lors de la version suivante, le concurrent rattrapait son retard, ce qui permettait de ne pas changer ses habitudes, alors que là ils ont fait le vide autour d’eux en quelques mois à peine... Mais bon, je ne veux pas paraître parano...

Une #guerre_culturelle comme la CIA sait les mener depuis longtemps.
Google a su forcer la main des optimistes béats de la technologie alors que les leaders d’opinion comme certain·es intellectuel·les inconscient·es tenaient un discours enchanteur sur la praticité informatique de cette firme (et des autres). Je ne sais comment l’amollissement de leur esprit, très certainement complexé de leur méconnaissance technique (mais oui, donnons le pouvoir aux enfants pour avoir des dictateurs tout neufs), les a rendu aussi incapables de voir que Google allait devenir un operating system au même titre qu’Apple ou Windows, mais avec une hégémonie particulièrement revendiquée de #BigBrother.
Pour ma part j’approfondirai un jour ma pensée du fait que mettre un pied dans Google est comparable à accepter de mourir.
POur la petite histoire je viens d’acheter un lave-linge avec la *%#@ robotisé de Google en cadeau, un truc qui se vend soit-disant à 60 euros et qui est entrain d’entrer par la petite porte de la gratuité (également via les opérateurs téléphonqiues) dans tous les foyers … je ne sais pas encore comment je vais noyer cette merde, si vous voulez la décortiquer, je vous l’envoie.
#boycott_google
Google a vite gagné des parts de marché parce que la page d’accueil était vide de toute publicité et qu’il ne faisait « que » moteur de recherche. Les autres moteurs étaient dans une soif (et un besoin) de monétisation qui nous exaspérait tous.
@biggrizzly : certes, mais encore une fois, je ne pense pas que ce soit un argument suffisant. Free offrait un serveur de courriel sans pub, ça lui a fait gagner quelques abonnés, mais il n’a pas renversé le marché...

C’est un effet cumulé, je me souviens qu’altavista c’etait assez performant pour la recherche d’image mais moins pour d’autres type de contenus et que google avait l’avantage d’être sobre, simple et de combiné plusieurs moteurs de recherche en un.
J’essaye de mon coté de passé sur Qwant depuis deux ou trois semaines mais presque systématiquement je trouve pas ce qui m’interesse et je doit doublé ma recherche sur gogol qui trouve ce que je veux :’(
Moi je suis passé à Searx.me
Il trouve, mais il est moche, il est lent, une fois sur deux il faut s’y prendre à deux fois, et depuis quelques jours il est automatiquement en anglais... Mais je m’accroche...
#moteur_de_recherche #Searx vs. #google #WSWS
#optimisation de #firefox

J’utilise #Qwant depuis qqs temps, c’est moins minimaliste que l’autre mais autant ne pas copier et être (un peu) original.
Ça trouve, c’est rapide... what else ?
Nouveau tag : #critiques_de pour recenser les critiques de #facebook, #google and co :
►https://seenthis.net/messages/670745
Traduction en français de l’article ici :
►https://seenthis.net/messages/713836
Depuis quelques temps, quand j’utilise #searx, les résultats sont moins bons, voire nuls et remplacés par la réponse suivante :
Erreur ! Les moteurs ne peuvent récupérer de résultats.
google (unexpected crash : CAPTCHA required)
Veuillez réessayer ultérieurement, ou utiliser une instance différente de searx.
Est-ce que vous comprenez le problème, et qu’est-ce que c’est une « instance différente de searx » ?
Merci !
Sur les conseils de @b_b je suis passé à ►https://searx.site mais 5 mois plus tard, à son tour de déconner. Comment savoir ceux qui marchent pour ne pas vous embêter à chaque fois ?
Cette liste les compilent :
►https://github.com/asciimoo/searx/wiki/Searx-instances
Il faut aussi qu’il existe comme « add on » de firefox, et du coup, en ce moment, je n’ai le choix qu’entre searx.me et searx.site Du coup, je repasse à searx.me... à suivre...
How the CIA made Google
Nafeez Ahmed, Medium, le 22 janvier 2015
►https://seenthis.net/messages/821822
Why Google made the NSA
Nafeez Ahmed, Medium, le 22 janvier 2015
►https://seenthis.net/messages/821822
#NSA
Le nouveau site d’évaluation des versions de Searx est ici :
►https://asciimoo.github.io/searx/user/public_instances.html
Les add-ons de Searx sur firefox sont là :
►https://addons.thunderbird.net/en-us/firefox/search/?q=searx&appver=72.0&platform=linux
Du coup, je passe à :
►https://searx.prvcy.eu

Qwant - Mon retour après 1 mois de test - Korben
►https://korben.info/qwant-mon-retour-apres-1-mois-de-test.html

Google renforce la mise sur liste noire des sites Web et des journalistes de gauche
▻http://www.wsws.org/fr/articles/2017/oct2017/goog-o21.shtml
Une recherche par Google News pour un article de l’édition du WSWS du jeudi ne renvoie aucun résultat
Le journaliste et auteur Chris Hedges, titulaire du prix Pulitzer, a informé le WSWS mercredi que ses articles avaient cessé d’apparaître sur Google News. Hedges a déclaré que le changement est survenu après la publication de son entretien [en anglais] avec le World Socialist Web Site dans lequel il a dénoncé la #censure par Google des sites de gauche.
« Quelque temps après avoir accordé cet entretien, ils m’ont mis sur liste noire », a déclaré Hedges. « Si vous allez dans Google News et tapez mon nom, il y a six articles, dont aucun n’a un rapport avec moi. »
Une recherche sur Chris Hedges par le biais de Google News ne renvoie aucun résultat pertinent
« J’écris constamment. Auparavant, Google News a listé mes articles pour Truthdig et mes contributions à Common Dreams et Alternet, ainsi que des références à mes livres », a déclaré Hedges. « Mais maintenant tout s’est volatilisé. Et je suis certain que c’est parce que je me suis prononcé contre la censure par Google. »
Google semble avoir conservé une version plus ancienne de son système d’agrégation de nouvelles disponible en ligne, accessible en se rendant sur google.com et en cliquant sur le lien news sous la barre de recherche. Cette version d’agrégation de nouvelles, qui semble être en voie de disparition, répertorie 254 000 résultats pour la recherche « World Socialist Web Site ».
De même, une recherche pour « Chris Hedges » renvoie 89 600 entrées.
Les changements apportés à Google News marquent une nouvelle étape dans une campagne systématique de censure et de mise sur liste noire qui a débuté au moins depuis avril, lorsque Ben Gomes, vice-président chargé de l’ingénierie, a déclaré que Google cherchait à promouvoir des médias « fiables » par rapport aux sources de nouvelles « alternatives ».
Depuis lors, treize principaux sites web de gauche ont vu un effondrement de 55 pour cent de leur fréquentation via le moteur de recherche de Google, de même pour le World Socialist Web Site qui a connu une chute de 74 pour cent de sa fréquentation depuis le moteur de recherche.
« Rien que du point de vue d’un journaliste, c’est terrifiant », a déclaré Hedges. « Ceux qui essaient toujours de faire du #journalisme, ce sont eux qui en pâtissent ; en particulier les journalistes qui tentent de s’attaquer aux problèmes de pouvoir et de l’intégration entre les grandes entreprises et l’État. »
« Cela montre non seulement comment l’état est en faillite, mais aussi combien il est effrayé », a déclaré Hedges.
« Google développe des méthodes de plus en plus intensive de #ciblage visant à bloquer toutes les voix critiques dissidentes », a déclaré David North, le président du comité de rédaction international du World Socialist Web Site.
« C’est une attaque sans précédent contre la liberté d’expression. Dans l’histoire des États-Unis, la censure à cette échelle n’a jamais été imposée en dehors de la guerre », a-t-il ajouté, soulignant le blocage des publications trotskystes pendant la Seconde Guerre mondiale.
Bien sur cela repose la question du #moteur_de_recherche alternatif qui remplacera #google sans y perdre par ailleurs. J’ai teste pas mal de sites sans jamais me decider pour l’un d’entre eux. Et vous ?

Non clairement, Google reste la référence en la matière. on ne peut pas le nier.


@sinehebdo : Personnellement j’utilise Qwant. Pas de cookies, pas de traçage de la navigation. Maintenant reste à savoir si Qwant ne ressert pas les indexations de Google. Pour faire remonter des infos, Seenthis est pas mal non plus ;-)
Effectivement, #Qwant reprend probablement les indexations de Google car World Socialist Web Site ne renvoie rien non plus dans la rubrique news...
▻https://www.qwant.com/?q=World%20Socialist%20Web%20Site%20&t=news
Duckduckgo ne donne rien non plus :
▻https://duckduckgo.com/?q=World+Socialist+Web+Site&t=h_&iar=news&ia=news
Et Ixquick n’a pas d’onglet « actualité »...
Problème pas facile à résoudre...

Dégooglisons internet trouvé sur le moteur de recherche, des chatons de Brest, signalé par @b_b et référencé ici, en 2016. @framasoft
▻https://seenthis.net/messages/497446
autrement, le fil d’info alternatif (c’est pas google actualités)
►http://www.lautrequotidien.fr/fil-rouge/2017/8/1/lautre-france-presse-international-bxka2
leur sources sont pour la plupart sur @seenthis
searx n’a pas non plus d’onglet « actualité »...
@sinehebdo je vois un onglet News dans les options avancées, mais je ne sais pas si le contenu renvoyé avec cette option est ce que tu cherches :\
Ah, effectivement, dans ce cas, ça marche :
▻https://searx.me/?q=World%20Socialist%20Web%20Site&categories=news&language=en-US
Donc c’est ►https://searx.me la meilleure alternative à Google aujourd’hui ?
@sinehebdo searx.me ou une de ses multiples instances cf :
►https://github.com/asciimoo/searx/wiki/Searx-instances
Et pourquoi pas ton propre searx en l’installant chez toi :
▻https://asciimoo.github.io/searx/dev/install/installation.html
Mais sinon l’instance #infini est très bien et maintenue par des gens sympas et ça se pourrait bien que ça soit le searx « le plus à l’ouest », et ça c’est tout de même classe :p

Problème cité dans le dernier édito du @mdiplo
►https://www.monde-diplomatique.fr/2018/01/RIMBERT/58251
« Dans un communiqué publié le 25 avril, M. Ben Gomes, vice-président de l’ingénierie de Google, a déclaré que la nouvelle version du moteur de recherche rétrograderait les sites “offensants”, et ferait remonter plus de “contenus faisant autorité” », écrivent Andre Damon et David North, du World Socialist Web Site (wsws.org, 2 août 2017). Aidé d’une société d’analyse de référencement, ce site trotskiste a mesuré les effets du nouvel algorithme qui, par défaut, présuppose les médias dominants fiables et la presse alternative louche. « On observe une perte importante de lectorat des sites socialistes, antiguerre et progressistes au cours des trois derniers mois, avec une diminution cumulée de 45 % du trafic en provenance de Google. » Entre mai et juillet 2017, les visites de wsws.org issues de Google ont chuté de 67 %, celles du réseau Alternet.org de 63 %. La plate-forme audiovisuelle Democracynow.org enregistre un plongeon de 36 % ; Counterpunch.org, de 21 % ; et Theintercept.com, de 19 %. « Dans la bataille contre les “fake news”, alerte l’association américaine Fairness and Accuracy in Reporting (FAIR) (1), une grande partie des reportages les plus indépendants et les plus précis sont en train de disparaître des résultats des recherches effectuées dans Google . » Tuer le pluralisme au nom de l’information ?


@whilelm c’est malin, je suis obligé de te désuivre maintenant :(
Une « grosse » mais c’était de l’humour (je fais semblant de blacklister celles et ceux qui signale ici un article de Rimbert ou Halimi (c’est kif kif) donc rien de grave, juste je m’amuse un peu, comme certain·es d’entre nous :) le font avec bhl ou finkielkraut.
En contre-jour, on pourrait prendre @reka pour une licorne…

@monolecte J’aime beaucoup l’image de la licorne parce que c’est un animal imaginaire et comme son nom l’indique, on peut imaginer ce qu’on veut dans un grand univers. Mais Wikipédia m’apprend que "une licorne est une startup, principalement de la Silicon Valley, valorisée à plus d’un milliard de dollars" . Je tiens à te rassurer, pour ce qui me concerne, ce n’est pas du tout du tout encore le cas :) ha ha ! Mais on peut rêver...
Voir aussi :
Le World Socialist Web Site appelle à une coalition de sites web socialistes et antiguerre pour contrer la censure sur Internet
Niles Niemuth, WSWS, le 19 janvier 2018
►https://seenthis.net/messages/662213
#World_Socialist_Web_Site #WSWS #journalisme #censure contre la politique pseudo #anti_fake_news de #facebook et de #Google
#optimisation de #firefox
Nouveau tag : #critiques_de pour recenser les critiques de #facebook, #google and co :
►https://seenthis.net/messages/670745
Depuis quelques temps, quand j’utilise #searx, les résultats sont moins bons, voire nuls et remplacés par la réponse suivante :
Erreur ! Les moteurs ne peuvent récupérer de résultats.
google (unexpected crash : CAPTCHA required)
Veuillez réessayer ultérieurement, ou utiliser une instance différente de searx.
Est-ce que vous comprenez le problème, et qu’est-ce que c’est une « instance différente de searx » ?
Merci !
@sinehebdo c’est un bug récurrent de searx, google ne facilite pas (sabote) la tâche pour qu’on puisse récupérer les résultats de la recherche dans ses pages, cf ces quelques liens :
▻https://github.com/asciimoo/searx/issues/1609
▻https://github.com/asciimoo/searx/issues/1608
▻https://github.com/asciimoo/searx/issues/729
▻https://github.com/asciimoo/searx/pull/1121
Pour les instances, il faut savoir que plein de monde propose un searx (chacun⋅e peut l’installer et le proposer à la communauté), et il y a une liste non exhaustive sur cette page :
►https://github.com/asciimoo/searx/wiki/Searx-instances
PS : celle qu’on propose chez #infini est en vrac en ce moment, désolé, mais on travaille pour la remettre sur pied.
Sur les conseils de @b_b je suis passé à ►https://searx.site mais 5 mois plus tard, à son tour de déconner. Comment savoir ceux qui marchent pour ne pas vous embêter à chaque fois ?
@sinehebdo la page que je citais sur le wiki du projet recense maintenant les instances dispos classées en fonction de leur état de fonctionnement ou non ;)
OK, merci, mais il faut aussi qu’il existe comme « add on » de firefox, et il cite searx.me et searx.site comme toujours « alive and running » alors que ce n’est pas mon expérience. Mais bon, je vais réessayer searx.me... à suivre... Encore merci !
Bon je recommence à vous embêter parce le add-on searx.me sur firefox me renvoie maintenant : « 405 Not Allowed »
Le nouveau site d’évaluation des versions est ici :
►https://asciimoo.github.io/searx/user/public_instances.html
Les add-ons de firefox sont là :
►https://addons.thunderbird.net/en-us/firefox/search/?q=searx&appver=72.0&platform=linux
Du coup, je passe à :
►https://searx.prvcy.eu
Indexer : Indexation
Cette page vise à documenter les paramètres de l’indexation dans le plugin Indexer, qui exploite le moteur de recherche Sphinx.
attendons que ce soit fini, éventuellement #pas_de_précipitation
no hurry, je le référencerai dans la gazette plus tard quand la doc sera sortie du carnet :)

#Rss : combien de divisions ?
▻http://www.dsfc.net/internet/veille/rss-combien-de-divisions
Seuls 30% des sites francophones disposent de flux #Atom/RSS/RDF.
#Veille #Formateur_Référencement_naturel #Formateur_SEO #Formateur_SMO #IFTTT #Moteur_de_recherche #Push #RDF #Référencement_naturel #SEO #SMO
2017 : un projet de #Moteur_de_recherche !?
▻http://www.dsfc.net/developpement/php-developpement/2017-un-projet-de-moteur-de-recherche
Je tiens à vous souhaiter tous mes vœux de réussite pour cette année 2017.
#Php #Formateur_MariaDB #Formateur_PHP #Full-Text_Search #MariaDB #MongoDB #php
#MySQL : la limite des 1000 caractères pour un index unique
▻http://www.dsfc.net/developpement/php-developpement/mysql-limite-1000-caracteres-index-unique
MySQL est limité à des colonnes de 1000 caractères pour ses index uniques !
#Php #Formateur_MariaDB #Formateur_MySQL #MariaDB #MD5 #Moteur_de_recherche
En route pour #Qwant Lite !
▻http://www.dsfc.net/internet/moteurs-internet/en-route-pour-qwant-lite
Il n’y a que les imbéciles qui ne changent pas d’avis ! Je passe à #Qwant_Lite.

Stop Using Google Trends
▻https://motherboard.vice.com/read/stop-using-google-trends
And we can see this with the most recent Google Trends Freaking Outrage (GTFO), like this Washington Post story titled “The British are frantically Googling what the E.U. is, hours after voting to leave it.”
They note that searches about the EU tripled. But how many people is that? Are they voters? Are they eligible to vote? Were they Leave or Remain? Trends doesn’t tell us, all it does is give us a nice graph with a huge peak. More likely, it’s a very small number of people, based on this graph that puts it in context with other searches in the region:
[...]
But it’s giving plenty of people cover to insult the entire country, when it’s likely just a few people searching for something in a way that they always search for something. It makes “The British are frantically Googling what the EU is, hours after voting to leave it” absurdly disingenuous without better numbers. Remy Smith points this out: The peak was merely ~1000 people! It’s ludicrous that so few people get turned into a massive story, but it underscores the need for context.
#Datavisualisation #Donnée #Google_Search #Google_Trends #Internet #Moteur_de_recherche #Politique #Sociologie #Statistique

#Qwant, le petit moteur de recherche anonyme qui monte
▻http://www.lemonde.fr/pixels/article/2016/06/22/qwant-le-petit-moteur-de-recherche-anonyme-qui-monte_4955968_4408996.html
Eric Leandri insiste sur la dimension éthique et sociétale de son aventure : « Avec notre technologie, nous pourrions gagner beaucoup d’argent en faisant du marketing de pointe, mais ce n’est pas notre intention. Nous voulons montrer qu’on peut gagner sa vie tout en ayant une pratique éthique, propre, respectueuse des droits et des modes de vie des Européens. Face à ceux qui veulent surveiller tout le monde tout le temps, nous proposons un autre projet de société, fondé sur la liberté individuelle. »
Par souci de transparence, Qwant a publié le code-source des logiciels utilisés par son service pour interagir avec les machines des utilisateurs : « Les gens qui savent lire le code peuvent vérifier que tout fonctionne réellement sans collecte de données. » En ce qui concerne les algorithmes de production des résultats, c’est plus compliqué : « Si nous les publions aujourd’hui, les spécialistes du référencement découvriraient notre méthode, et trouveraient des moyens pour favoriser artificiellement tel ou tel site. Nous travaillons sur une solution technique ambitieuse : dès 2017, nous espérons publier en #open-source des algorithmes qui ne seront pas détournables, grâce à notre système d’intelligence artificielle et à la technique de la “blockchain” [répertoire distribué infalsifiable]. »
Terrapattern
▻http://www.terrapattern.com
“similar-image search” for satellite photos. It’s an open-source tool for discovering “patterns of interest” in unlabeled satellite imagery—a prototype for exploring the unmapped, and the unmappable.
(...) Terrapattern is ideal for discovering, locating and labeling typologies that aren’t customarily indicated on maps. These might include ephemeral or temporally-contingent features (such as vehicles or construction sites), or the sorts of banal infrastructure (like fracking wells or smokestacks) that only appear on specialist blueprints, if they appear at all.
(...) the Terrapattern prototype is intended to demonstrate a workflow by which users—such as journalists, citizen scientists, humanitarian agencies, social justice activists, archaeologists, urban planners, and other researchers—can easily search for visually consistent “patterns of interest”. We are particularly keen to help people identify, characterize and track indicators which have not been detected or measured previously, and which have sociological, humanitarian, scientific, or cultural significance.
▻http://www.newyorker.com/tech/elements/meet-terrapattern-google-earths-missing-search-engine
#photographie #satellite #IA #neural_network #moteur_de_recherche #cartographie
Ici aussi ►http://seenthis.net/messages/493168 et dans tes étoiles en plus :)
La version lite de #Qwant plutôt pas mal, même si…
▻http://www.dsfc.net/internet/moteurs-internet/la-version-lite-de-qwant-plutot-pas-mal-meme-si
Il reste à Qwant de s’autonomiser réellement par rapport à Bing et de s’étendre sur la recherche dans les réseaux sociaux et la recherche de vidéos.
#Moteurs #Moteur_de_recherche #Moteurs_de_recherche #Qwant_Lite

Encore un site Web (très bien, par ailleurs), qui dépendait de Google pour son trafic et qui découvre soudain que Google fait ce qu’il veut.



























































{kind=link}